With the rise of internet-connected devices and applications, data interchange has become inevitable. It is important for these communications to happen in a secure [2], yet efficient manner keeping in mind resource bottlenecks — network, processor, and disk resources.
[visibility type=”hidden-phone”]
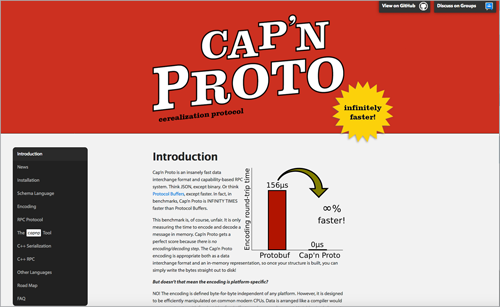
Cap’n Proto is a fast data interchange format and capability-based RPC system. It’s infinitely times faster than protocol buffers.
Protocol buffers started at Google as their data interchange format [1]. It then evolved to be a tool used by many applications and services instead of JSON, XML, etc. Cap’n Proto [2] is a similar tool, developed by Xoogler Kenton Varda, as part of the Sandstorm project [3], but is far more efficient with advanced capabilities than Protobuf. Before the advent of these tools, XML and JSON were the common standard formats used for data interchange.
So what do these tools offer that JSON and XML don’t? Cap’n Proto and other similar serialization tools offer several advantages: JSON and XML are text-based formats, so data has to be passed character by character and hence are slower and verbose. On the other hand, Protobuf and Cap’n Proto are binary-based formats, hence are often faster and more efficient in terms of space. The size of messages sent on the wire by these formats is significantly smaller when compared to JSON and XML formats [4].
All these formats typically have a ‘schema,’ which defines the structure of a message. As applications evolve over time, it is essential to have schema evolution with support for backward compatibility: you can update or change the schema with different versions, and it should still continue to work. Backward compatibility is needed especially in big production systems when you decide to add more features or update various components, without having to worry about breaking existing ones. This cannot be achieved easily with JSON and XML, but can easily be done using Cap’n Proto or Protobuf.
A schema file is created which defines the format, structure, and types of various fields in the message. A compiler is used to generate code from a schema file and which provides some nifty accessors and setter methods. Using this generated code, you can read and write messages easily without having to worry about breaking anything.
Following is a simple sample schema definition in Cap’n Proto for communicating heavy hitters in the case of DDoS attack:
interface HeavyhittersDataProducts{
sendHeavyHitters @0 (hitters: List(HeavyHitter)) -> ();
struct HeavyHitter{
srcIp @0: Text; # Source IP address
dstIp @1: Text; # Destination IP address
srcPort @2: UInt32; # Source Port number
dstPort @3: UInt32; # Destination Port number
}
}
The sendHeavyHitters() is a method that transmits a list of hitters to a given endpoint. The structure for a hitter is defined in the HeavyHitter structure. The field names and types are separated by ‘:’, and the ‘@’ denotes how fields evolved over time to support backward compatibility. You can add more fields such as protocol, timestamp, etc. without breaking the structure.
You can generate source code from the schema by compiling it using the Cap’n Proto compiler for C++. For example, one types ‘capnpc -oc++ hitters.capnp’, where capnpc is the Cap’n Proto compiler, hitter.capnp is the schema file.
A small snippet from a C++ application which imports the generated code header is shown below to demonstrate how messages can be written:
//Assuming connection between client and server is already setup...
auto request = cap_client.sendHeavyHittersRequest();
::capnp::List<::HeavyhittersDataProducts::HeavyHitter>::Builder hitter = request.initHitters(5); // Initializes 5 hitter instances
// setter methods for each field follows below
hitter[0].setDport(22);
hitter[0].setSrcip("0.0.0.0");
hitter[0].setDstip("0.0.0.1");
hitter[1].setDport(443);
...
Note the use of “Builder” for building messages for initializing Hitters. A “Reader” pointer may be used to read serialized messages on the other end. Some additional fields may be omitted while building the message, without incurring any space overhead.
A note on Cap’n Proto–when we’re building a Cap’n Proto structure, we’re actually working with this already serialized data in memory. The idea is analogous to a zero-copy mmap(), but using “Reader” and “Writer” pointers from the generated code. Hence, this is much faster in practice compared to other similar tools such as Protobuf.
To summarize, these language agnostic tools offer much better performance benefits in terms of speed and space compared to conventional JSON and XML data interchange formats. Also, some of these tools have a built-in RPC system, which makes it very convenient to use. These tools are supported on various languages including Java, C++, Go, Ruby, Python, Javascript, etc. For some of these reasons many large-scale systems today, including systems at Facebook and Google (among many others), use these tools. Merit Research uses Cap’n Proto’s RPC and Serialization in the AMON network monitoring tool [6].
If you are interested in learning more about Cap’n Proto [2] or similar tools (Google’s Protocol buffers [1], Apache’s Thrift [7], Zeroc Ice [8], etc), please check out the official websites for more explanation and examples.
[1] https://developers.google.com/protocol-buffers/[2] https://capnproto.org/
[3] https://sandstorm.io/
[4] Sumaray, A., Makki, S.K., “A comparison of data serialization formats for optimal efficiency on a mobile platform,” In Proceedings of the 6th International Conference on Ubiquitous Information Management and Communication, ICUIMC 2012, Kuala Lumpur, Malaysia, pp. 48:1–48:6. ACM, New York (2012)
[5] AMON: An open-source framework for multi-gigabit network monitoring Part I: real-time traffic visualization: https://www.merit.edu/amon-an-open-source-framework/
[6] M. Kallitsis and S. A. Stoev and S. Bhattacharya and G. Michailidis. AMON: An Open Source Architecture for Online Monitoring, Statistical Analysis, and Forensics of Multi-Gigabit Streams. IEEE Journal on Selected Areas in Communications, Volume: 34, Issue: 6, Pages: 1834-1848, June 2016
[7] https://thrift.apache.org/
[8] https://zeroc.com/